Projects for Meemoo
(November 2018-Present)
Meemoo is a nice mid sized company in the center of Gent Dampoort Belgium. They handle the archiving and digitizing of a lot of video and audio content. Both used in education and used to archive television station data for later re-use. This means managing prete huge data sets with archives. Building exciting services on top of amazon S3. Communicating with various systems for exchanging meta data and basically a lot of development work to be done here.
I started working at Meemoo around november of 2018 (it was then still called VIAA). First I had a contract till june of 2019, however this has been extended various times into 2021 because a lot of new projects came in that I would enjoy working on. Originally I only started on the Indexer and GraphQL for onderwijs.hetarchief.be But As you can see below this quickly grew into many other projects doing various transformations on data, api's, ldap interfaces, user management tools. Mailing tools, bulk user operations etc. Mostly a mix of various backend projects either in python/flask or ruby sinatra+rails and frontend work either with some vanilla javascript or for larger gui's in react.js.
Also as mentioned on my blog they're the first company that I work at as contractor that open sources some of their projects. This is great as for almost all the companies I've worked at in the past heavily rely on open source frameworks, programming languages and tools. But somehow most of them don't contribute back to the open source community much (for various reasons). I've contributed almost all my sparetime and 'personal hobby' projects back to the open source community but I was basically never allowed to share any code written during the office hours. It's nice to finally see that happening now.

Indexer for Elastic Search
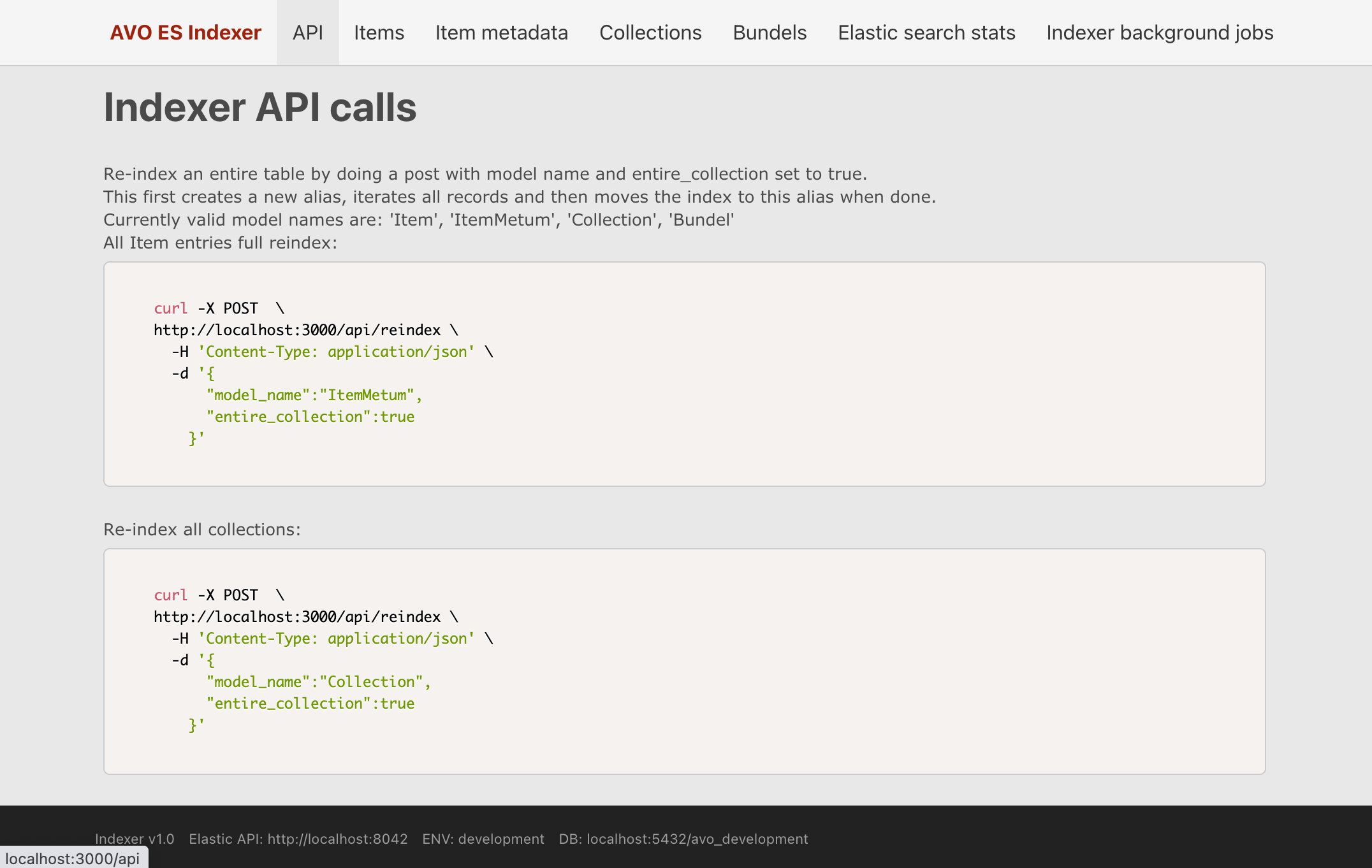
For this task I wrote a Rails application that synchronizes data from postgres database into Elastic Search. It also serves webhook endpoints used by GrapQL api used by onderwijs.hetarchief.be
It uses sidekiq workers to have low latency for all requests and does all the heavy lifting using sidekiq workers in the background. For python people this is something much like celery workers combined with Flower. IMHO Sidekiq however is more mature and more stable than celery when used in production.
In the screenshot you can see this rails application exposes a json api for doing various tasks and that is also used by the hasura webhooks. It also has some pages to view and check the data in the current database (items, item meta etc.). And it has a status page for seeing the items in the elastic search. Finally it also exposes the sidekiq management pages to reschedule jobs if any have failed.
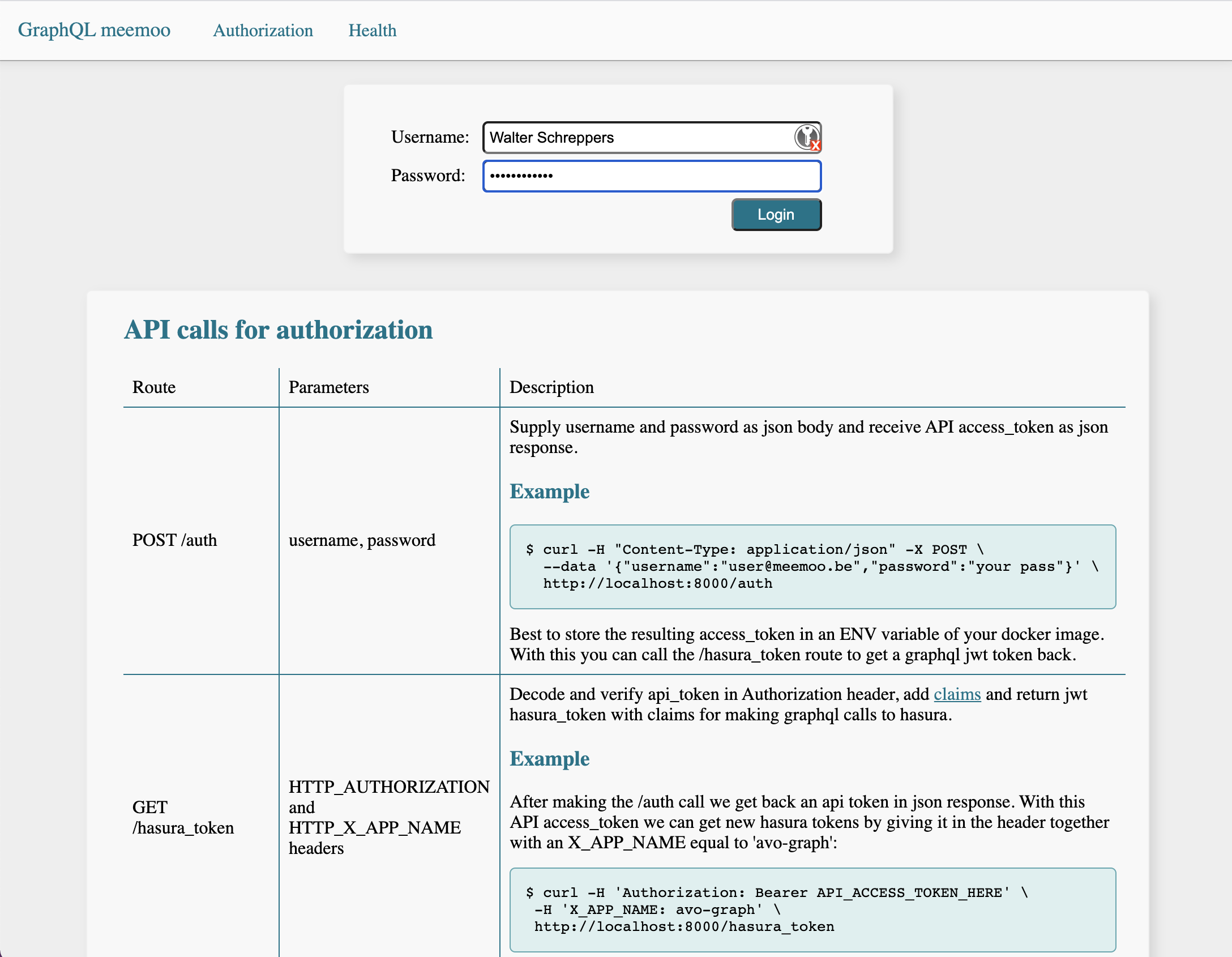
Authorize v2 application for GraphQL
Authorization using jwt tokens. It allows creating new auth jwt tokens (requesting on /auth route) and also has webhooks and other routes needed for authorization of the graphql api used by onderwijs.hetarchief.be. The authorize app has some endpoints to generate and return a jwt token which then allows access with a certain role onto the graphql backend api running on hasura
GraphQL API for AVO version 2
Hasura GraphQL API with many tables, views, permissions and custom graphql queries are possible to fetch data on our postgres database. Furthermore it also has various triggers calling the Indexer to update counts for video views, bookmarks, plays etc. It also works together with the Authorize application.
S3 proxy server for VRT and other content partners
Ruby sinatra web application that sits between VRT and Caringo S3 servers. It allows customization needed for supporting S3 archive/restoring of video data. And is heavily used by VRT and other news stations in order to have a nice simple S3 interface to their archived media content.
LDAP-API
LDAP-API written in ruby on rails using swagger. It has a nice json interface allowing to interact with an Open LDAP server for storing all the users of various systems like www.hetarchief.be, onderwijs.hetarchief.be. This was initially written by Laurens De la marche. But I took over the project when he left to another company and made it work for production. Fixing various bottlenecks and improving+extending the api whenever needed.
LDAP SSUM
Rails application also fully written by myself. It allows SAML logins, registrations, password forget forms, email password reset links etc. Basically everything regarding the accounts of various systems including hetarchief.be and onderwijs.hetarchief.be. It first worked standalone but was later refactored to work through LDAP-API.
Apart from registrations, it also includes sending emails for password forget links and single login/logout with SAML and blocking automated scripting logins by using re-captcha v2 (and v3). And finally it allows account modification by the users themselves (hence the acronym SSUM which stands for Self Service User Management).
The interface also enforces stronger passwords by displaying a strength meter that validates you didn't use your name, email or dictionary words or some of the common passwords used. It is however allowed to write longer passwords with little sentences and also allows auto generation of passwords from your browser.
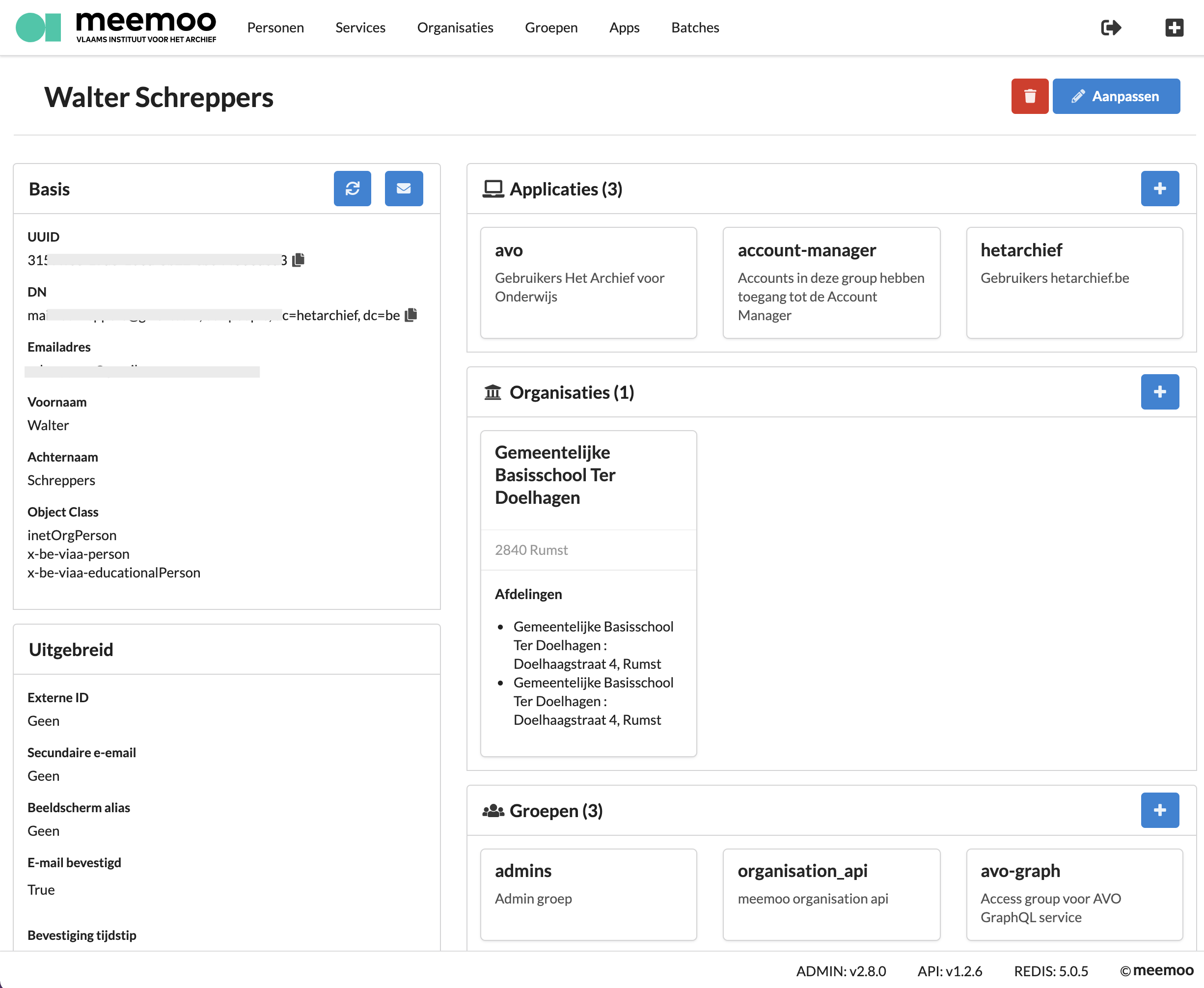
Account Manager
A nice react js application running on rails to basically server mostly javascript react pages. Also written by other contractors but I've worked on it and improved + extended it with many features during 2020.
One of large features was bulk updating of accounts and various bulk changes to be done by uploading a csv file. It can also mass email various student groups for notifying or subscribing them to the new avo platform. It has nice logging using websockets now and this plays nicely with the LDAP-API mentioned above.
All data is stored and retreived using the ldap-api. And presented using nicely styled graphical components written as React Components using semantic-ui and bootstrap for styling. The nice thing about using react is that various pages have a nice undo feature that would be way harder to get right when doing this with traditional server side rendered pages. In this screen you see a preview of one of the pages and when you click on edit pretty much every field and box is editable. Some fields have multi selects and dropdowns done with semantic-ui and other fields are built with complete custom react components allowing re-using them on various pages.
GraphQL API for events logging
Another hasura api but this one is used by various projects both back and frontend to log events happening within a system. This makes centralised overview of a chain of events between various web services easier to follow. For instance the LDAP-SSUm logs a registration, Avo react frontend logs the user logging in, Account Manager logs the blocking of same user because he did something bad etc.
Metadatacatalogus
A mid sized Ruby on Rails application. Basically the pages you see at hetarchief.be. This was mostly developed by other contractors and I've occotionally made a few small patches and code reviews for merge requests here. It's pretty stable and hasn't needed much maintenance nor improvements at all during the time I've worked there.
Singe file upload frontend
This is a react.js frontend written by other contractors. That does need some work to be finalized/more user friendly. I've only worked a day on it once or twice. I might however resume work on this in the future (depends on the planning).
VRT metadata micro services
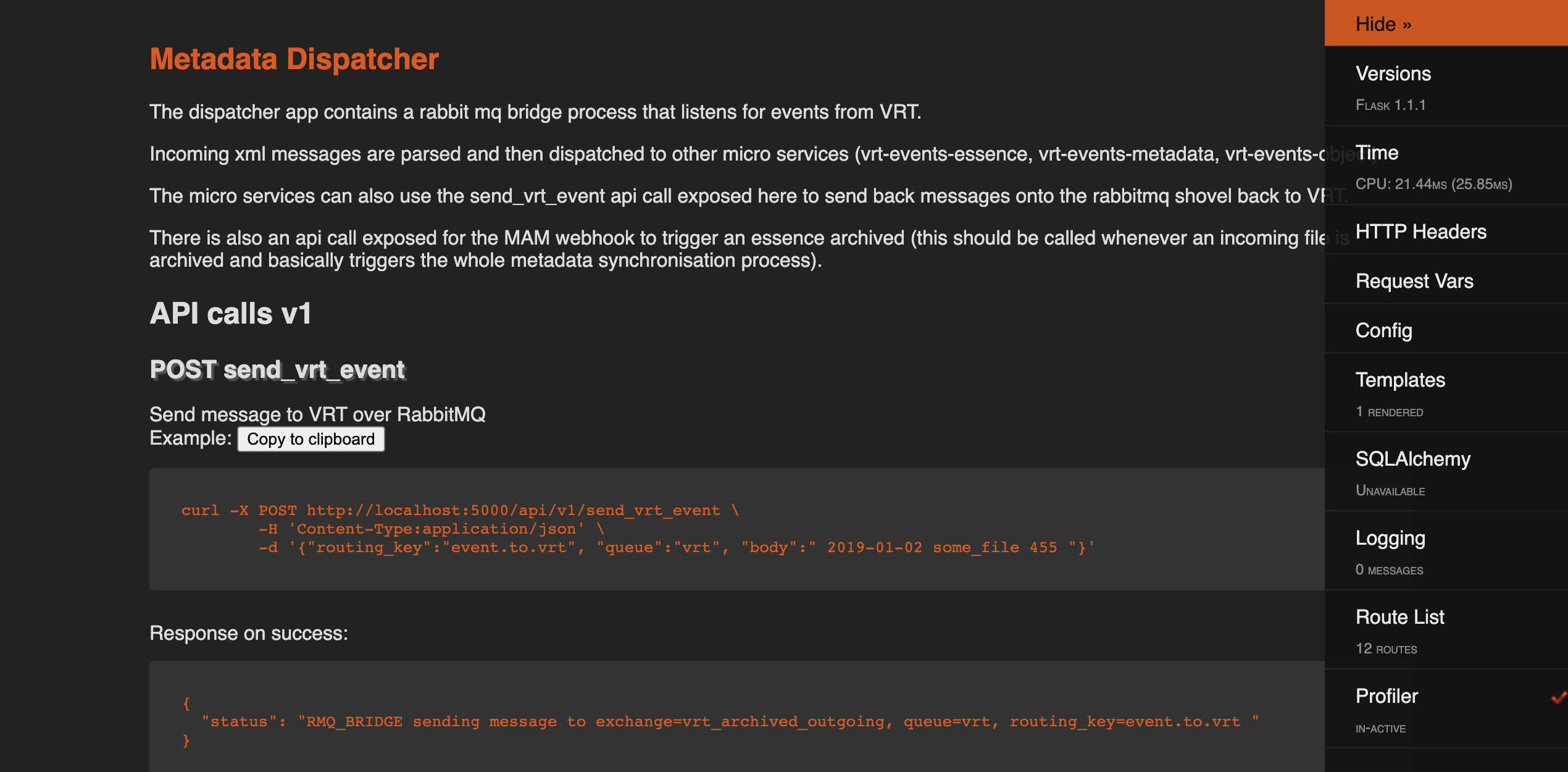
Four smaller flask micro services communicating over a shared RabbitMQ to synchronize data and handle various events being sent by the VRT to Meemoo over RabbitMQ. By having an event dispatcher it was easy to step from rabbit queues into simple web requests so that the other smaller micro services only needed to be simple rest-like services with some threading for performance of longer requests. Along the way some xml is being sent and validated and transformed and various calls to Mediahaven API need to be made in various circumstances.
Written from scratch in a 2-3 weeks and then handed over to other inhouse developers who then used this prototype as starting point to build the more extended versions that are in use in production now.
Syncrator-API
Small json api using jwt tokens for authorization. Allows you to start/stop docker images using a syncrator to sync data between various databases and elastic search, solr etc. Basically syncrator in the Meemoo context has a similar job as Octopus in the ETS Engie group it links various data sources and apis together and fills in the necessary data for other projects to function. Syncrator is written in ruby and has performed it's job the past years pretty consistently without much maintenance. However it does suffer from some threading issues that need to be fixed. Also it can be tedious to implement new features here because it links so many different data sources and targets.
Similar to my hints about Octopus, in the long run syncrator could/can be fased out into some smaller micro services. We could then just alter the syncrator-api to call these smaller services under the hood so that to the outside world/other components nothing much changes. However it will simplify working on various features. Basically syncrator suffers from the same burdon on trying to accomplish too many things in one large project. Its always nicer to be able to split it up into smaller more manageable chunks. This also would allow to rewrite the smaller chunks in python or any other future language/framework that pops up. Micro services really shine in that you can alter blocks whenever you have a little spare time. Allowing a certain component to grow too large and take on many duties makes it harder to make such changes to a different language or framework.
The syncrator-api that allows calling various syncrator jobs using simple json requests with curl was recently open sourced. I was happy about this decision, so I wrote some blogpost about it here
The syncrator-api has also become a public git repo. You can view my work on it here
Subloader
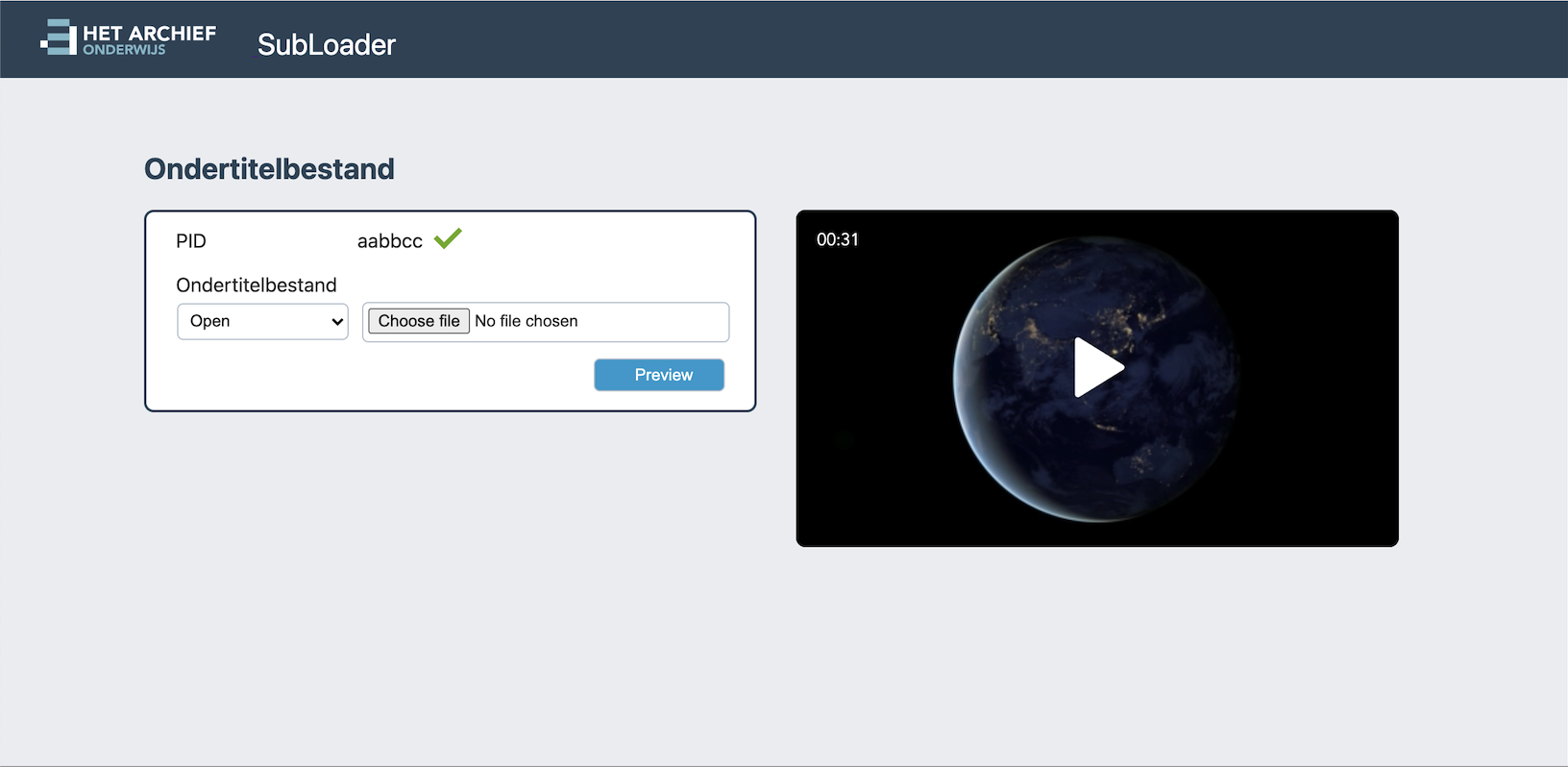
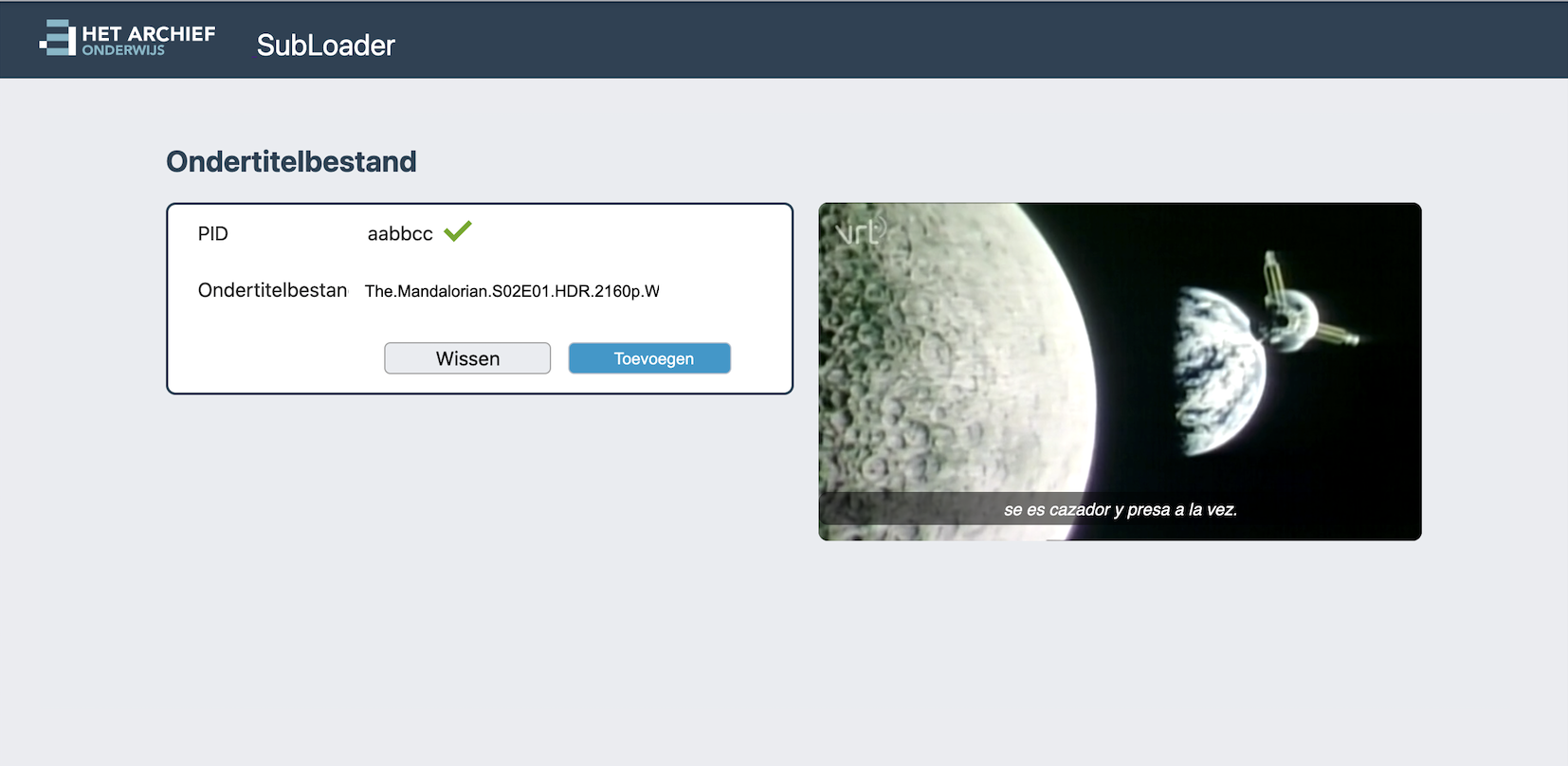
Small application written in 2 weeks to manage uploading new subtitles for videos shown in The new AVO2 platform. This was a drupal application that performed terribly under load. Using GraphQL in the backend, Elastic Search, some of the above micro services and adding a nice snappy React.js frontend by studio hyperdrive made the new platform way more responsive and faster. Also code maintenence is much easier and overal satisfaction both by the students and developers working on it has been great.
The subloader is a small part of the many backend pages used to manage the content of onderwijs.hetarchief.be and it was written in just a week (then extended some more and after all bugfixes in 2 weeks it went to production). Short time to production but it did get fully finished, with nice testing code coverage and also recently got open sourced. I was happy about this decision, so I wrote some blogpost about it here
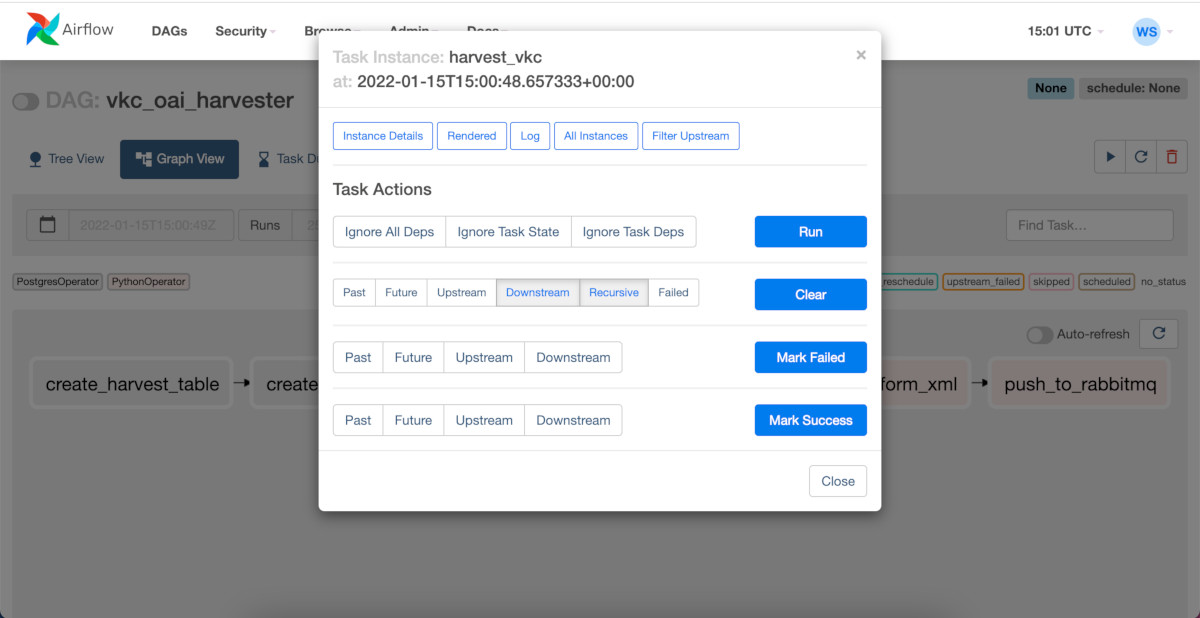
Vlaamse Kunstcollectie data harvesting with Airflow
For another project at Meemoo we needed to harvest data from the Vlaamse Kunstcollectie. To do this efficiently we used the Apache Airflow framework. This allows us to extract the open available xml data and then do some xml transformations and store the transformed data into a database. The extraction runs basically iterate over all pages exposed by VKC and then harvest + transform the data to be used in other projects for instance for Machine Learning or just archiving purposes.
Teamleader2DB and Teamleader2LDAP
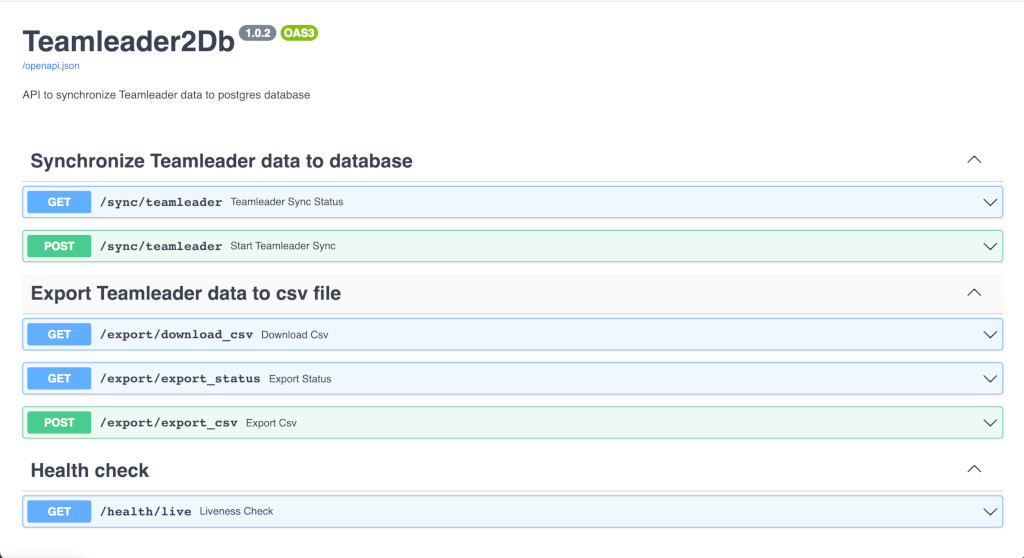
To keep track of our Teamleader data we created a project called Teamleader2DB. This project heavily uses Python FastApi.
In essance it allows for automatically syncing teamleader data into a database for backup and restore purposes. There is another Teamleader2LDAP project which replaces another MuleSoft project and syncs all related teamleader data to our LDAP servers at Meemoo. Teamleader2LDAP replaces a legacy MuleSoft application. Both projects we're developed over the course of 1 or 2 months and fully replace some proprietary MuleSoft applications.
Redactietool
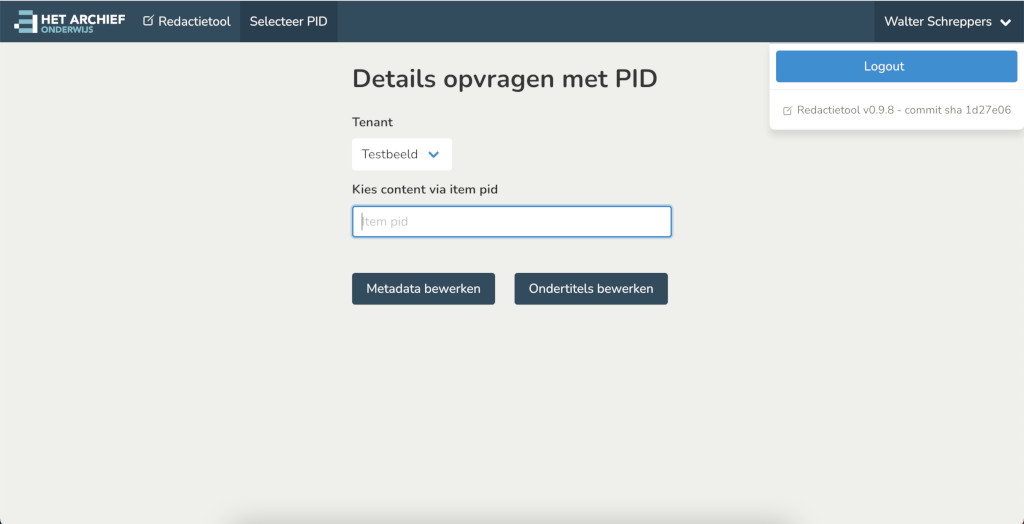
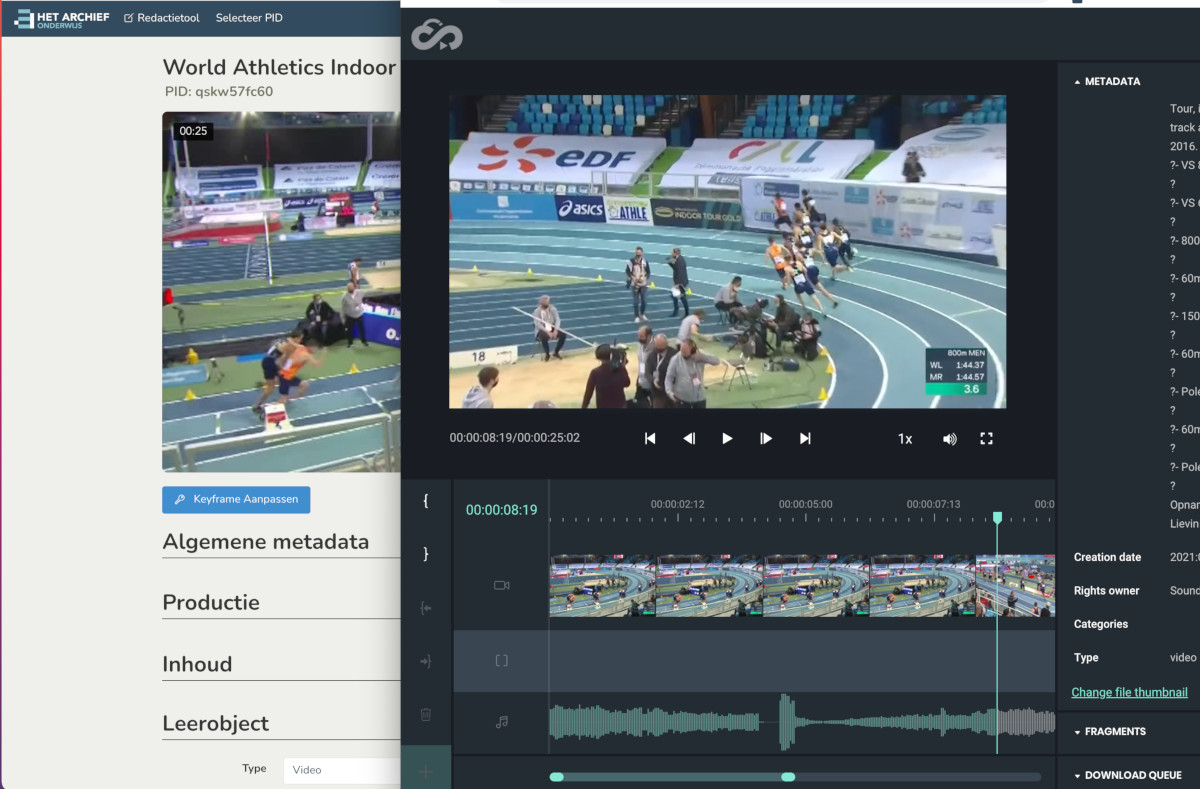
After the success of subloader. The project was extended to also incorporate editing of more metadata. This involved adding rich components using Vue.js javascript framework. A complete restyling using bulma css. And overal polishing of all the subloader pages and then extending this with a lot more features to easily redact archived video and audio clips.
Development is fully in progress now and it's also open sourced here on github: Redactietool GIT repository
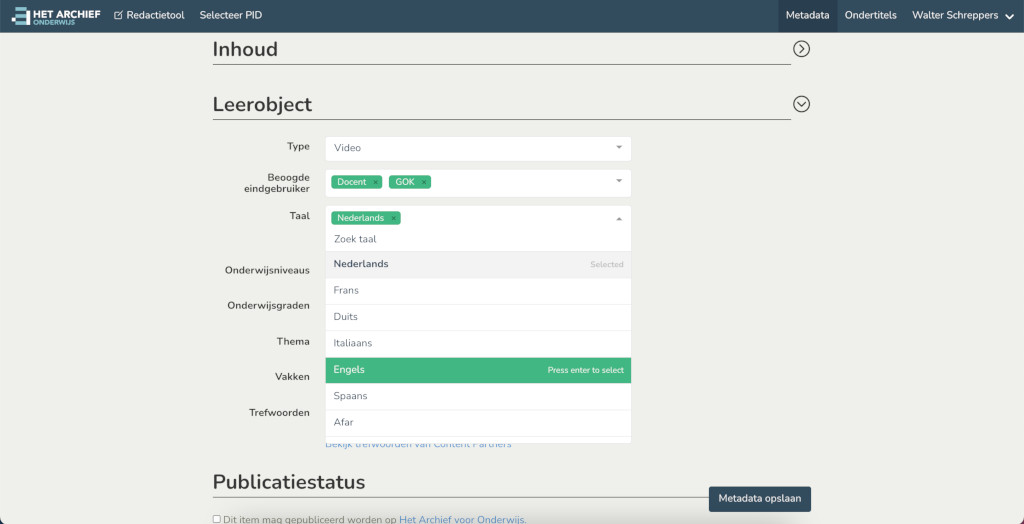
Redactietool does many things like picking the keyframe for videos. Upload and preview subtitles. Edit various metadata elements. At it's core it has a giant dynamic metadata edit form that acts differently depending on the data it is supplied from Mediahaven json api. It links to other services like the Suggest library which can give suggestions based on the user's selections in the Leerobject section. The makers, bijdragers, publishers are also dynamic nested forms and many fields selectively show various types of videos, series, podcasts etc.
We also moved to SAML authentication so it integrates nicely with the other in-house tools (you only sign in once and can use all tools without the need to re-login).
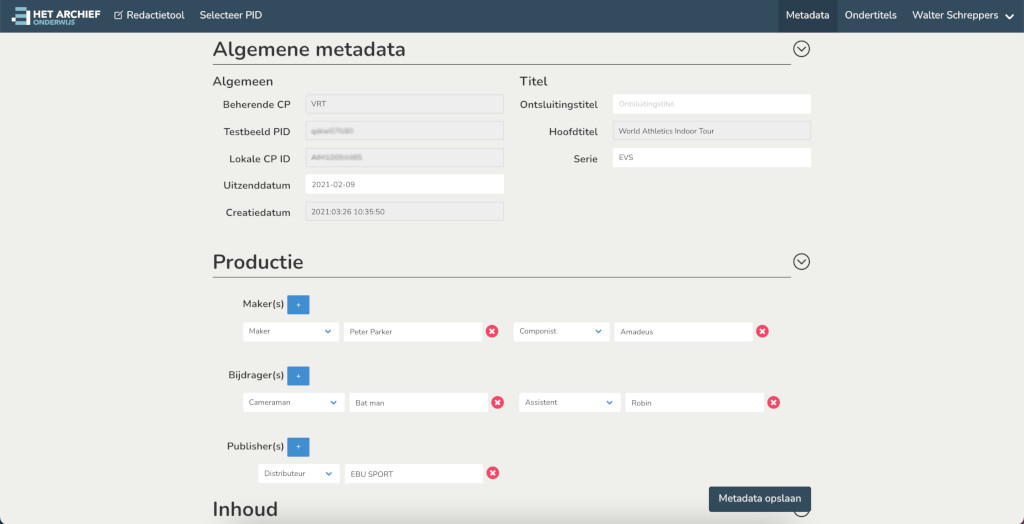
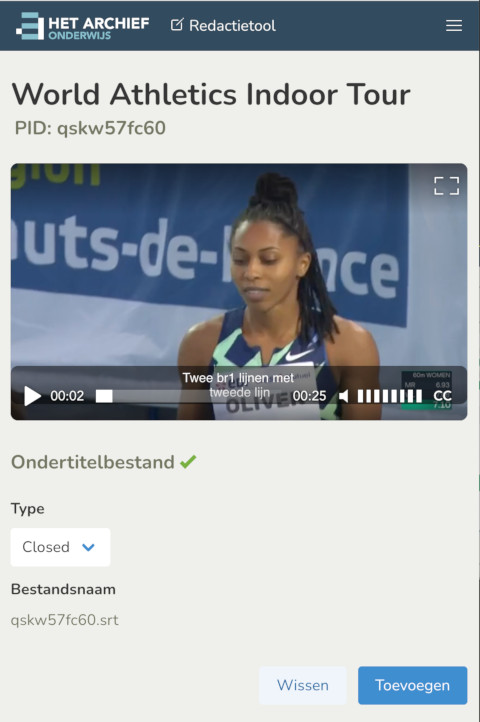
And because of the excellent new bulma css framework most pages we're already responsive and mobile ready out of the box. Even the burger dropdown menu for mobiles went effordlessly. I highly recommend bulma for any future smartphone or tablet sites.
For most other projects done in 2021 I've used a mix of fast-api, airflow and starlette as frameworks. But for this we reverted to python flask as the original subloader tool was also in flask and because we used a SAML authentication library also suited to be used in flask as well.
Conclusions
Meemoo is a great place with nice people to work with. There's a good vibe and relaxed atmosphere. You do have to perform and meet sometimes tight deadlines but it's the right balance of enough time to do things properly and enough work to keep you occopied every day. This allows you to write clean software and have time to write proper tests for your code and overal makes the daily job of software development more pleasant.
During 2021 many more projects we're completed and now my contract was just extended to work further together in 2022.